diff --git a/app.js b/app.js
index 21963b0..010bc73 100644
--- a/app.js
+++ b/app.js
@@ -109,7 +109,7 @@ app.get('/bnp/changelog', (req, res) => {
return res.render('pages/post', postData)
})
-const port = 3000
+const port = 5000
app.listen(port, () => console.log('Example app listening on port ' + port + '!'))
module.exports = app
diff --git a/posts/basic-http-routing-in-golang.html b/posts/basic-http-routing-in-golang.html
deleted file mode 100644
index a423f9e..0000000
--- a/posts/basic-http-routing-in-golang.html
+++ /dev/null
@@ -1,129 +0,0 @@
-Basic HTTP Routing in Golang
-Golang is incredibly powerful. Its standard library has so much to offer, but I think other languages have encouraged the use of external libraries for even the most basic tasks. For example, with JavaScript, most inexperienced developers seem to use jQuery to do simple tasks like selecting an element and replacing its contents. When you and I both know jQuery is way overkill for such a task. See my article on Vanilla JS basics.
-I believe that in order to be considered an expert in a language, you must at least be able to demonstrate using the core language to achieve your goal. In our current case, HTTP routing. Now to be clear, I don't think you need to write everything from scratch all the time, but you should have a firm grasp on what is available by the core language, and when you are better suited to use an external library. If you are looking for more advanced HTTP routing, then I would suggest using something like gin.
-Enough ranting, let's get to it.
-Assumptions
-I assume you have basic knowledge of the Go language at this point, so if not, it might be worth searching for some entry level basics first. See A Tour of Go.
-Let's begin
-The accompanying repo for the code produced in this article is located on github.
-Step 1
-Here is our basic folder structure for this basic http routing example:
- basic-http-routing-in-golang/
- main.go
-
-As a starting point our main.go file looks like this:
- package main
-
- import (
- "fmt"
- _ "net/http"
- )
-
- func main() {
- fmt.Println("Hello HTTP")
- }
-
-Step 2
-Now starting at a very basic level, we can leverage the http.HandleFunc method.
-It is very simple to use and its signature is easy to understand.
- func HandleFunc(pattern string, handler func(ResponseWriter, *Request))
-
-Which basically means, http.HandleFunc("/url", routingFunction) where routingFunction looks like this:
- func routingFunction(w http.ResponseWriter, req *http.Request) {
- fmt.Fprint(w, "Hello HTTP")
- }
-
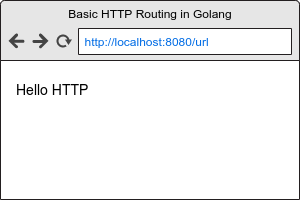
-With fmt.Fprint() we can pass an http.ResponseWriter and a message to display. Our browser will now look like this when we visit the /url endpoint.
-
-Here is what main.go looks like at this point:
- package main
-
- import (
- "fmt"
- "log"
- "net/http"
- )
-
- func main() {
- http.HandleFunc("/hello", helloHTTP)
- log.Fatal(http.ListenAndServe(":8080", nil))
- }
-
- func helloHTTP(w http.ResponseWriter, req *http.Request) {
- fmt.Fprint(w, "Hello HTTP")
- }
-
-Now we could stop there, as this is a "basic" http routing example, but I think it isn't quite useful as an example yet, until we start to see something slightly more practical.
-Step 3
-So let's add a NotFound page when we don't match a pattern in HandleFunc. It's as simple as:
- func notFound(w http.ResponseWriter, req *http.Request) {
- http.NotFound(w, req)
- }
-
-Here is what main.go looks like after that:
- package main
-
- import (
- "fmt"
- "log"
- "net/http"
- )
-
- func main() {
- http.HandleFunc("/hello", helloHTTP)
- http.HandleFunc("/", notFound)
- log.Fatal(http.ListenAndServe(":8080", nil))
- }
-
- func helloHTTP(w http.ResponseWriter, req *http.Request) {
- fmt.Fprint(w, "Hello HTTP")
- }
-
- func notFound(w http.ResponseWriter, req *http.Request) {
- http.NotFound(w, req)
- }
-
-This will match /hello and use the HelloHTTP method to print "Hello HTTP" to the browser. Any other URLs will get caught by the / pattern and be given the http.NotFound response to the browser.
-So that works, but I think we can go further.
-Step 4
-We need to give ourselves something more specific than the simple contrived /hello endpoint above. So let's assume we are needing to get a user profile. We will use the url /user/:id where :id is an identifier used to get the user profile from our persistance layer (i.e. our database).
-We'll start by creating a new method for this GET request called userProfile:
- func userProfile(w http.ResponseWriter, req *http.Request) {
- userID := req.URL.Path[len("/user/"):]
- fmt.Fprintf(w, "User Profile: %q", userID)
- }
-
-Notice that we get the URL from the req variable and we treat the string returned from req.URL.Path as a byte slice to get everything after the /user/ in the string. Note: this isn't fool proof, /user/10ok would get matched here, and we would be assigning userID to "10ok".
-Let's add this new route in our main function:
- func main() {
- http.HandleFunc("/hello", helloHTTP)
- http.HandleFunc("/user/", userProfile)
- http.HandleFunc("/", notFound)
- log.Fatal(http.ListenAndServe(":8080", nil))
- }
-
-Note: that this pattern /user/ matches the trailing / so that a call to /user in the browser would return a 404 Not Found.
-Step 5
-Ok, so we have introduced some pretty severe holes in the security of our new HTTP router. As mentioned in a note above, treating the req.URL.Path as a byte slice and just taking the last half is a terrible idea. So let's fix this:
- var validPath = regexp.MustCompile("^/(user)/([0-9]+)$")
-
- func getID(w http.ResponseWriter, req *http.Request) (string, error) {
- m := validPath.FindStringSubmatch(req.URL.Path)
- if m == nil {
- http.NotFound(w, req)
- return "", errors.New("Invalid ID")
- }
- return m[2], nil // The ID is the second subexpression.
- }
-
-Now we can use this method in our code:
- func userProfile(w http.ResponseWriter, req *http.Request) {
- userID, err := getID(w, req)
- if err != nil {
- return
- }
- fmt.Fprintf(w, "User Profile: %q", userID)
- }
-
-Conclusion
-For now, I'm calling this "Basic HTTP Routing in Golang" article finished. But I do plan to add more to it as time allows. Additionally, I'd like to create a more advanced article that discusses the ability to respond to not only GET requests, but also POST, PUT, and DELETE HTTP methods. Look for an "Advanced HTTP routing in Golang" article in the future. Thanks for reading this far. I wish you well in your Go endeavors.
\ No newline at end of file
diff --git a/posts/basic-http-routing-in-golang.json b/posts/basic-http-routing-in-golang.json
deleted file mode 100644
index 126e5b0..0000000
--- a/posts/basic-http-routing-in-golang.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "title": "Basic HTTP Routing in Golang - Levi Olson",
- "permalink": "/posts/basic-http-routing-in-golang",
- "created_at": "2018-05-09T11:52:50-06:00",
- "created_at_short": "2018-05-09",
- "post_title": "basic http routing in golang",
- "active": "posts",
- "content_file": "basic-http-routing-in-golang.html"
-}
diff --git a/posts/basic-http-routing-in-golang.md b/posts/basic-http-routing-in-golang.md
deleted file mode 100644
index 0135eb2..0000000
--- a/posts/basic-http-routing-in-golang.md
+++ /dev/null
@@ -1,174 +0,0 @@
-# Basic HTTP Routing in Golang #
-
-Golang is incredibly powerful. Its standard library has so much to offer, but I think other languages have encouraged the use of external libraries for even the most basic tasks. For example, with JavaScript, most inexperienced developers seem to use jQuery to do simple tasks like selecting an element and replacing its contents. When you and I both know jQuery is way overkill for such a task. [See my article on Vanilla JS basics](https://leviolson.com/posts/vanilla-js-basics).
-
-I believe that in order to be considered an expert in a language, you must at least be able to demonstrate using the core language to achieve your goal. In our current case, HTTP routing. Now to be clear, I don't think you need to write everything from scratch all the time, but you should have a firm grasp on what is available by the core language, and when you are better suited to use an external library. If you are looking for more advanced HTTP routing, then I would suggest using something like [gin](https://github.com/gin-gonic/gin).
-
-Enough ranting, let's get to it.
-
-## Assumptions ##
-
-I assume you have basic knowledge of the Go language at this point, so if not, it might be worth searching for some entry level basics first. See [A Tour of Go](https://tour.golang.org).
-
-## Let's begin ##
-
-The accompanying repo for the code produced in this article is located [on github](https://github.com/leothelocust/basic-http-routing-in-golang).
-
-### Step 1 ###
-
-Here is our basic folder structure for this basic http routing example:
-
- basic-http-routing-in-golang/
- main.go
-
-
-As a starting point our `main.go` file looks like this:
-
- package main
-
- import (
- "fmt"
- _ "net/http"
- )
-
- func main() {
- fmt.Println("Hello HTTP")
- }
-
-
-### Step 2 ###
-
-Now starting at a very basic level, we can leverage the [`http.HandleFunc`](https://golang.org/pkg/net/http/#HandleFunc) method.
-
-It is very simple to use and its signature is easy to understand.
-
- func HandleFunc(pattern string, handler func(ResponseWriter, *Request))
-
-
-Which basically means, http.HandleFunc("/url", routingFunction) where `routingFunction` looks like this:
-
- func routingFunction(w http.ResponseWriter, req *http.Request) {
- fmt.Fprint(w, "Hello HTTP")
- }
-
-
-With `fmt.Fprint()` we can pass an `http.ResponseWriter` and a message to display. Our browser will now look like this when we visit the `/url` endpoint.
-
-
-
-Here is what `main.go` looks like at this point:
-
- package main
-
- import (
- "fmt"
- "log"
- "net/http"
- )
-
- func main() {
- http.HandleFunc("/hello", helloHTTP)
- log.Fatal(http.ListenAndServe(":8080", nil))
- }
-
- func helloHTTP(w http.ResponseWriter, req *http.Request) {
- fmt.Fprint(w, "Hello HTTP")
- }
-
-
-Now we could stop there, as this is a "basic" http routing example, but I think it isn't quite useful as an example yet, until we start to see something slightly more practical.
-
-### Step 3 ###
-
-So let's add a `NotFound` page when we don't match a pattern in `HandleFunc`. It's as simple as:
-
- func notFound(w http.ResponseWriter, req *http.Request) {
- http.NotFound(w, req)
- }
-
-
-Here is what `main.go` looks like after that:
-
- package main
-
- import (
- "fmt"
- "log"
- "net/http"
- )
-
- func main() {
- http.HandleFunc("/hello", helloHTTP)
- http.HandleFunc("/", notFound)
- log.Fatal(http.ListenAndServe(":8080", nil))
- }
-
- func helloHTTP(w http.ResponseWriter, req *http.Request) {
- fmt.Fprint(w, "Hello HTTP")
- }
-
- func notFound(w http.ResponseWriter, req *http.Request) {
- http.NotFound(w, req)
- }
-
-
-This will match `/hello` and use the `HelloHTTP` method to print "Hello HTTP" to the browser. Any other URLs will get caught by the `/` pattern and be given the `http.NotFound` response to the browser.
-
-So that works, but I think we can go further.
-
-### Step 4 ###
-
-We need to give ourselves something more specific than the simple contrived `/hello` endpoint above. So let's assume we are needing to get a user profile. We will use the url `/user/:id` where `:id` is an identifier used to get the user profile from our persistance layer (i.e. our database).
-
-We'll start by creating a new method for this GET request called `userProfile`:
-
- func userProfile(w http.ResponseWriter, req *http.Request) {
- userID := req.URL.Path[len("/user/"):]
- fmt.Fprintf(w, "User Profile: %q", userID)
- }
-
-
-Notice that we get the URL from the `req` variable and we treat the string returned from `req.URL.Path` as a byte slice to get everything after the `/user/` in the string. **Note: this isn't fool proof, `/user/10ok` would get matched here, and we would be assigning `userID` to `"10ok"`.**
-
-Let's add this new route in our `main` function:
-
- func main() {
- http.HandleFunc("/hello", helloHTTP)
- http.HandleFunc("/user/", userProfile)
- http.HandleFunc("/", notFound)
- log.Fatal(http.ListenAndServe(":8080", nil))
- }
-
-
-_Note: that this pattern `/user/` matches the trailing `/` so that a call to `/user` in the browser would return a `404 Not Found`._
-
-### Step 5 ####
-
-Ok, so we have introduced some pretty severe holes in the security of our new HTTP router. As mentioned in a note above, treating the `req.URL.Path` as a byte slice and just taking the last half is a terrible idea. So let's fix this:
-
- var validPath = regexp.MustCompile("^/(user)/([0-9]+)$")
-
- func getID(w http.ResponseWriter, req *http.Request) (string, error) {
- m := validPath.FindStringSubmatch(req.URL.Path)
- if m == nil {
- http.NotFound(w, req)
- return "", errors.New("Invalid ID")
- }
- return m[2], nil // The ID is the second subexpression.
- }
-
-
-Now we can use this method in our code:
-
- func userProfile(w http.ResponseWriter, req *http.Request) {
- userID, err := getID(w, req)
- if err != nil {
- return
- }
- fmt.Fprintf(w, "User Profile: %q", userID)
- }
-
-
-## Conclusion ##
-
-For now, I'm calling this "Basic HTTP Routing in Golang" article finished. But I do plan to add more to it as time allows. Additionally, I'd like to create a more advanced article that discusses the ability to respond to not only GET requests, but also POST, PUT, and DELETE HTTP methods. Look for an "Advanced HTTP routing in Golang" article in the future. Thanks for reading this far. I wish you well in your Go endeavors.
diff --git a/posts/bnp-changelog.html b/posts/bnp-changelog.html
deleted file mode 100644
index 25b32ec..0000000
--- a/posts/bnp-changelog.html
+++ /dev/null
@@ -1,69 +0,0 @@
-Better Network Panel - Changelog
-
-
-Version 1.0.1
-
-Panel Settings
-A new panel has been added that contains some configurable items.
-
-  -
-
-Various Bugfixes and Enhancements
-
-- SCSS refactor for better handling of page size changes (i.e. using flexbox)
-- User can enable/disable auto-scrolling of network logs (See Panel Settings)
-- Search terms now have better CSS cursor indicators
-
-
-Version 1.0.0
-
-  -
-
-
-Improved Search
-Advanced search capability has been added in this release which improves on the previous search by adding a negation search (i.e. "-carts" which would remove requests containing "carts" in the results).
-
-  -
-
-Additionally, AND and OR searching filters have been added. So you can search for:
-
- products AND services
-
-Which would return any request containing BOTH products AND services somewhere in the headers, request body, etc…
-And you can search for:
-
- products OR services
-
-Which would return any requests containing EITHER products OR services.
-
-JSON Editor BUILT IN
-Using the Open Source JSON Editor, you can now easily search and view JSON data just as you can on the official jsoneditoronline.org website.
-
-  -
-
-
-Vertical Chrome Panel
-Better Network Panel now supports a vertical layout using responsive CSS. Panel resizing will be released soon.
-
-  -
-
-
-Download JSON
-Download the current panel as a JSON doc.
-
-  -
-
\ No newline at end of file
diff --git a/posts/bnp-changelog.json b/posts/bnp-changelog.json
deleted file mode 100644
index ba8d755..0000000
--- a/posts/bnp-changelog.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "title": "Better Network Panel - Changelog - Levi Olson",
- "permalink": "/posts/bnp-changelog",
- "created_at": "2021-01-23T10:05:19-06:00",
- "created_at_short": "2021-01-23",
- "post_title": "Better Network Panel - Changelog",
- "active": "",
- "content_file": "bnp-changelog.html"
-}
\ No newline at end of file
diff --git a/posts/bnp-changelog.md b/posts/bnp-changelog.md
deleted file mode 100644
index a6b4a2a..0000000
--- a/posts/bnp-changelog.md
+++ /dev/null
@@ -1,98 +0,0 @@
-# Better Network Panel - Changelog
-
-
-
-
-
-## Version 1.0.1
-
-
-
-### Panel Settings
-
-A new panel has been added that contains some configurable items.
-
-
- 
-
-
-### Various Bugfixes and Enhancements
-
-* SCSS refactor for better handling of page size changes (i.e. using flexbox)
-* User can enable/disable auto-scrolling of network logs (See [Panel Settings](#panel-settings))
-* Search terms now have better CSS cursor indicators
-
-
-
-## Version 1.0.0
-
-
- 
-
-
-
-
-### Improved Search
-
-Advanced search capability has been added in this release which improves on the previous search by adding a negation search (i.e. "-carts" which would remove requests containing "carts" in the results).
-
-
- 
-
-
-
-Additionally, **AND** and **OR** searching filters have been added. So you can search for:
-
-> `products` **AND** `services`
-
-Which would return any request containing **BOTH** `products` **AND** `services` somewhere in the headers, request body, etc...
-
-And you can search for:
-
-> `products` **OR** `services`
-
-Which would return any requests containing **EITHER** `products` **OR** `services`.
-
-
-
-### JSON Editor BUILT IN
-
-Using the Open Source [JSON Editor](https://github.com/josdejong/jsoneditor), you can now easily search and view JSON data just as you can on the official [jsoneditoronline.org](https://jsoneditoronline.org) website.
-
-
- 
-
-
-
-
-### Vertical Chrome Panel
-
-Better Network Panel now supports a vertical layout using responsive CSS. Panel resizing will be released soon.
-
-
- 
-
-
-
-
-### Download JSON
-
-Download the current panel as a JSON doc.
-
-
- 
-
diff --git a/posts/chrome-ext-better-network-panel.html b/posts/chrome-ext-better-network-panel.html
deleted file mode 100644
index df13ce4..0000000
--- a/posts/chrome-ext-better-network-panel.html
+++ /dev/null
@@ -1,24 +0,0 @@
-Better Network Panel - a Chrome extension
-
- "As a Salesforce and Vlocity developer, I'm constantly looking for ways to improve my workflow, speed up my debugging, and find answers fast."
-
-THE PROBLEM
-Over the last couple months, part of my debugging process has involved using the Chrome DevTools "Network" panel to find a specific apexremote call. The search to find one apexremote call out of dozens has been… annoying.
-The page loads, several dozen apexremote calls flood the panel, and I start clicking each one, until the correct one (i.e. Request-Body contains "xyz") and I can proceed to look at the Preview.
-The issue has only just begun, as I need to inspect the Response, perform some searches for IDs and the like, and although the Response is JSON format, the node in the response I need to search is stringified in a child member. So I must copy the data, parse it somehow, either locally on my machine or on the web (jsoneditoronline.org has been great) and finally perform the searching I need.
-And all of the above is done several times a day.
-THE SOLUTION
-
-I present to you a Better Network Panel. A Chrome extension that adds a new panel, and offers great features like:
-
-- Full Search - Entire request is searchable (i.e. headers, request body, etc…), not just URI
-- JSON Parsing - Even nested members that contain stringified JSON are parsed to 3 levels deep
-- JSON Search - Incremental searching is available directly in the Preview pane
-- Regex Search - Powerfull regex searches can be performed on the Preview pane
-- More to come
-
-Open source baby
-View it on GitHub
-Special Thanks
-A huge thanks and recognition goes to Milton Lai and his project SAML Chrome Panel. I started from a fork of his project, but later started fresh as there was a lot of SAML specific code that this project doesn't use/need. The UI is nearly identical, but the code underneath has become fairly different at this point.
-The SAML Chrome Panel was a huge help and ispiration! Thank you Milton and contributors to the SAML Chrome Panel project!
\ No newline at end of file
diff --git a/posts/chrome-ext-better-network-panel.json b/posts/chrome-ext-better-network-panel.json
deleted file mode 100644
index b178eba..0000000
--- a/posts/chrome-ext-better-network-panel.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "title": "Better Network Panel - a Chrome Extension - Levi Olson",
- "permalink": "/posts/chrome-ext-better-network-panel",
- "created_at": "2020-10-04T17:55:13-33:00",
- "created_at_short": "2020-10-04",
- "post_title": "better network panel - a chrome extension",
- "active": "posts",
- "content_file": "chrome-ext-better-network-panel.html"
-}
\ No newline at end of file
diff --git a/posts/chrome-ext-better-network-panel.md b/posts/chrome-ext-better-network-panel.md
deleted file mode 100644
index 8bf444e..0000000
--- a/posts/chrome-ext-better-network-panel.md
+++ /dev/null
@@ -1,35 +0,0 @@
-# Better Network Panel - a Chrome extension
-
-> "As a Salesforce and Vlocity developer, I'm constantly looking for ways to improve my workflow, speed up my debugging, and find answers fast."
-
-## THE PROBLEM
-
-Over the last couple months, part of my debugging process has involved using the Chrome DevTools "Network" panel to find a specific `apexremote` call. The search to find one `apexremote` call out of dozens has been... annoying.
-
-The page loads, several dozen `apexremote` calls flood the panel, and I start clicking each one, until the correct one (i.e. `Request-Body` contains "xyz") and I can proceed to look at the Preview.
-
-The issue has only just begun, as I need to inspect the `Response`, perform some searches for `ID`s and the like, and although the `Response` is JSON format, the node in the response I need to search is stringified in a child member. So I must copy the data, parse it somehow, either locally on my machine or on the web (jsoneditoronline.org has been great) and finally perform the searching I need.
-
-And all of the above is done several times a day.
-
-## THE SOLUTION
-
-[](https://chrome.google.com/webstore/detail/better-network-panel/kknnkgpbclaljhfcknhbebhppmkmoaml)
-
-I present to you a [Better Network Panel](https://chrome.google.com/webstore/detail/better-network-panel/kknnkgpbclaljhfcknhbebhppmkmoaml). A Chrome extension that adds a new panel, and offers great features like:
-
-* **Full Search** - Entire request is searchable (i.e. headers, request body, etc...), not just URI
-* **JSON Parsing** - Even nested members that contain stringified JSON are parsed to 3 levels deep
-* **JSON Search** - Incremental searching is available directly in the Preview pane
-* **Regex Search** - Powerfull regex searches can be performed on the Preview pane
-* More to come
-
-## Open source baby
-
-View it on [GitHub](https://github.com/leothelocust/better-network-chrome-panel)
-
-## Special Thanks
-
-A huge thanks and recognition goes to [Milton Lai](https://github.com/milton-lai/saml-chrome-panel) and his project SAML Chrome Panel. I started from a fork of his project, but later started fresh as there was a lot of SAML specific code that this project doesn't use/need. The UI is nearly identical, but the code underneath has become fairly different at this point.
-
-The SAML Chrome Panel was a huge help and ispiration! Thank you Milton and contributors to the SAML Chrome Panel project!
diff --git a/posts/i-can-crack-your-password.html b/posts/i-can-crack-your-password.html
deleted file mode 100644
index 44dad5b..0000000
--- a/posts/i-can-crack-your-password.html
+++ /dev/null
@@ -1,133 +0,0 @@
-You may think your password is secure. Maybe you have chosen an obscure word, mixed in numbers, and added a
- ! to the end. Think you’re pretty safe, huh?
-
-The truth is, you aren’t. I can crack a 5 character password in less then 139 seconds!
-
-We have been trained over time, by
- unproven security techniques, to make our passwords contain numbers and letters; sometimes even an
- @ or
- # or
- ! is added to the mix.
- But the truth is, we are only making it harder on ourselves with passwords that are difficult to remember, but
- easy to guess in a brute-force attack (automated hacking software).
-
-Although a 128-character
- totally random password would be phenomenal, 8 characters is about all that can be enforced without frustrating
- users. However, an 8-character password comprised of uppercase, lowercase, and numbers can be cracked overnight in a
- real world brute-force attack.
-
-The Scoop on Alpha-Numeric Passwords
-
-Even though we are trained to think that a password of
- Blu3D0g5 is the most secure type of password, it can still be cracked by a brute-force attack.
-
-
-Bare with me while I explain…
- with some maths!
-
-
-For every character in an alpha-numeric password there are
- 62 possibilities. First, you have the
- 26 character alphabet in lowercase, then
- 26 more in uppercase, and
- 10 digits.
-
-
-
-This is to say that if you choose 8 characters,
- completely at random, your password would be very secure. However, we typically take a familiar word, or couple
- of words, and add some uppercase letters, or replace
- e with
- 3, etc… which is
- not secure.
-
-When we calculate the Information Entropy (known as the lack of order or predictability) we can see that a completely random
- character set is great, but when it is derived from an English word, or contains a date, it is simply terrible. The equation
- looks like this:
-
-
-
[Password_Length] * log2([Number_of_Possibilities]) = "Information Entropy"
-
-
8 * log2(62) = "~48 bits"
-# which would take almost 9,000 years at 1,000 guesses per second
-
- But, when your password isn’t
- completely random, it’s not that simple.
-
-
-Because the password we chose was actually two words,
- blue and
- dogs, with some uppercase and numbers mixed in, the total Entropy is
- MUCH less. Something closer to
- ~28 bits.
-
-
- So let’s calculate what this actually means. A brute-force attacker can easily guess 1,000 times per second.
- The total number of options to guess can be calculated by taking the base 2 to the total number of bits.
-
-
-
2^28 = 268,435,456
-# This is the total number of possibilities the password could be.
-
In theory though, an attacker only needs to guess about half the total number of options before stumbling upon the correct
- one. So:
-
-
-
268,435,456 / 2 = 134,217,728
-# Total number of guesses it takes to guess your password
-
-134,217,728 / 1,000 = ~134,218
-# At 1,000 guesses per second, it takes about 134,218 seconds
-
-134,218 / 60 = ~2,237
-# Or 2,237 minutes
-
-2,237 / 60 = ~37
-# Or 37 hours to guess your password
-
-
-In Contrast
-
-Let’s say we use 4
- random words, without any numbers, and all lowercase. For example:
- yellow
- tiger
- note
- basket. There are an incalculable amount of words for you to choose from, but most likely, you will choose from
- about 7,000 of the most commonly used words. If you use unique words like
- laggardly or
- pomological, the total time to crack your password will increase
- exponentially!
-
-Using this new data, the Information Entropy is now calculated as:
-
-
-
[Number_of_words] * log2(7,000)
-
So, this new password now has
- ~51 bits of Entropy, and using the same time calculations above, we estimate our password would take about
- 35,702 years to crack at the rate of 1,000 guesses per second.
-
-That is in stark contrast to the short 37 hours it takes to crack the
- Blu3D0g5 password.
-
-
-
-The Take Away
-
-By simply increasing the length of our passwords and using words randomly mixed together, we can have the most secure passwords
- that attackers will struggle to figure out, but that we can actually remember. I personally will never forget
- yellow
- tiger
- note
- basket as long as I live. However, now I can’t use it.
\ No newline at end of file
diff --git a/posts/i-can-crack-your-password.json b/posts/i-can-crack-your-password.json
deleted file mode 100644
index f61defb..0000000
--- a/posts/i-can-crack-your-password.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "title": "I can crack your password - Levi Olson",
- "permalink": "/posts/i-can-crack-your-password",
- "created_at": "2018-04-27T07:05:32-06:00",
- "created_at_short": "2018-04-27",
- "post_title": "i can crack your password",
- "active": "posts",
- "content_file": "i-can-crack-your-password.html"
-}
\ No newline at end of file
diff --git a/posts/something-decent.html b/posts/something-decent.html
deleted file mode 100644
index 05debca..0000000
--- a/posts/something-decent.html
+++ /dev/null
@@ -1,4 +0,0 @@
-
- the start of something... decent
-
-I don't expect to have a lot to say, but when I do, I'd like a place to put it.
\ No newline at end of file
diff --git a/posts/something-decent.json b/posts/something-decent.json
deleted file mode 100644
index d7580b1..0000000
--- a/posts/something-decent.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "title": "Something Decent - Levi Olson",
- "permalink": "/posts/something-decent",
- "created_at": "2018-04-27T05:05:19-06:00",
- "created_at_short": "2018-04-27",
- "post_title": "the start of something... decent",
- "active": "posts",
- "content_file": "something-decent.html"
-}
\ No newline at end of file
diff --git a/posts/vanilla-js-basics.html b/posts/vanilla-js-basics.html
deleted file mode 100644
index afad550..0000000
--- a/posts/vanilla-js-basics.html
+++ /dev/null
@@ -1,79 +0,0 @@
-Vanilla JS Basics
-
- Warning: This article turned out to be a bit of rant. So if you are the type to get offended when I say negative things
- about JavaScript, you are welcome to leave.
-
-JavaScript is what I consider to be an "easy" language. Now what do I mean by that? Well, its usually the first
- scripting language that new developers learn, and you can get started with very little "training". It
- has a relatively simple syntax. It can be very powerful. So from my point of view, its an easy language to pick up. And
- therein lies the problem.
-So many of the JavaScript programmers out there today hear the term "JavaScript" and think in there mind "jQuery".
- Now that's great to have that kind of brand recognition if you are jQuery, but if you are looking to be an efficient
- programmer that doesn't put holes in everything you make, you may want to consider that JavaScript is NOT jQuery.
-Additionally, we need to start thinking about the consequences of using third-party libraries for everything. Longer load
- times, additional security risks, more memory consumption, and the list goes on.
-I want to give you at least a few little snippets of vanilla JavaScript that will get you on your way to not importing jQuery
- on every project as a
- step 1. It should be near the end of your steps and only as needed.
-
- Disclaimer: Vanilla JavaScript will be longer (i.e. more verbose), but this isn't always a bad thing. Keep in mind that
- we are eliminating the import of another package, and all the bloat that comes with it.
-
-Assumptions
-For starters, I'm assuming that you getting this far means that you at least have heard of JavaScript. If you have not heard
- of jQuery,
- leave now, I don't want "introducing someone to jQuery" to be what you get out of this.
-Let's begin...
-Selecting Element in the DOM
-jQuery
- $('#myID')
-
-Vanilla JavaScript
- document.getElementById('myID')
-
-Again, note that vanilla JavaScript is longer, but its actually more descriptive of what is going on here. Unless you are
- familiar with jQuery (yes, I know you are) the jQuery syntax doesn't tell you what its doing.
-Replace Text/HTML in the DOM
-jQuery
- $('#myID').html('here is the replacement')
-
-Vanilla JavaScript
- document.getElementById('myID').innerHTML('here is the replacement')
-
-Very similar eh. However, there is actually some performance gain by using vanilla JavaScript. See
- here.
-Click Handling in the DOM
-jQuery
- $('#myID').click(function() {
- alert('Clicked it!')
- })
-
-Vanilla JavaScript
- document.getElementById('myID').addEventListener('click', function(e) {
- alert('Clicked it!')
- })
-
-So easy.
-Advanced Queries and Iteration
-jQuery
- $('.item').hide()
-
-Vanilla JavaScript
- var items = document.getElementsByClassName('.items')
- for (var i = 0; i < items.length; i++) {
- item[i].style.display = 'none'
- }
-
-We're starting to see the verbosity I mentioned above, but again, remember that we aren't loading in a massive third-party
- library!
-Even More Advanced
-See Patrick Kunka's article
- A Year Without jQuery
-
-Patrick and I agree on many of the same points and his article articulates some helper functions that can be used to perform
- more advanced loops, child selection and child indexing. I highly recommend you read through his article.
-Conclusion
-If you find that your requirements heavily rely on JavaScript for DOM manipulation, or that you need animations such as the
- ones provided by jQuery, then don't let me stop you. But if you only need some of what was covered above, or you want
- to put a priority on performance, then you should really consider going with plain vanilla JavaScript and leave the dependencies
- behind. You won't regret it.
\ No newline at end of file
diff --git a/posts/vanilla-js-basics.json b/posts/vanilla-js-basics.json
deleted file mode 100644
index 92c6e98..0000000
--- a/posts/vanilla-js-basics.json
+++ /dev/null
@@ -1,9 +0,0 @@
-{
- "title": "Vanilla JS Basics - Levi Olson",
- "permalink": "/posts/vanilla-js-basics",
- "created_at": "2018-05-10T13:33:12-06:00",
- "created_at_short": "2018-05-10",
- "post_title": "vanilla js basics",
- "active": "posts",
- "content_file": "vanilla-js-basics.html"
-}
\ No newline at end of file
diff --git a/posts/vanilla-js-basics.md b/posts/vanilla-js-basics.md
deleted file mode 100644
index 68b9de2..0000000
--- a/posts/vanilla-js-basics.md
+++ /dev/null
@@ -1,84 +0,0 @@
-# Vanilla JS Basics #
-
-_Warning: This article turned out to be a bit of rant. So if you are the type to get offended when I say negative things about JavaScript, you are welcome to leave._
-
-JavaScript is what I consider to be an "easy" language. Now what do I mean by that? Well, its usually the first _scripting_ language that new developers learn, and you can get started with very little "training". It has a relatively simple syntax. It can be very powerful. So from my point of view, its an easy language to pick up. And therein lies the problem.
-
-So many of the JavaScript programmers out there today hear the term "JavaScript" and think in there mind "jQuery". Now that's great to have that kind of brand recognition if you are jQuery, but if you are looking to be an efficient programmer that doesn't put holes in everything you make, you may want to consider that JavaScript is NOT jQuery.
-
-Additionally, we need to start thinking about the consequences of using third-party libraries for everything. Longer load times, additional security risks, more memory consumption, and the list goes on.
-
-I want to give you at least a few little snippets of vanilla JavaScript that will get you on your way to not importing jQuery on every project as a _step 1_. It should be near the end of your steps and only as needed.
-
-_Disclaimer: Vanilla JavaScript will be longer (i.e. more verbose), but this isn't always a bad thing. Keep in mind that we are eliminating the import of another package, and all the bloat that comes with it._
-
-## Assumptions ##
-
-For starters, I'm assuming that you getting this far means that you at least have heard of JavaScript. If you have not heard of jQuery, **leave now**, I don't want "introducing someone to jQuery" to be what you get out of this.
-
-Let's begin...
-
-### Selecting Element in the DOM ###
-
-jQuery
-
- $('#myID')
-
-Vanilla JavaScript
-
- document.getElementById('myID')
-
-Again, note that vanilla JavaScript is longer, but its actually more descriptive of what is going on here. Unless you are familiar with jQuery (yes, I know you are) the jQuery syntax doesn't tell you what its doing.
-
-### Replace Text/HTML in the DOM ###
-
-jQuery
-
- $('#myID').html('here is the replacement')
-
-Vanilla JavaScript
-
- document.getElementById('myID').innerHTML('here is the replacement')
-
-Very similar eh. However, there is actually some performance gain by using vanilla JavaScript. See [here](https://stackoverflow.com/questions/3563107/jquery-html-vs-innerhtml#answer-3563136).
-
-### Click Handling in the DOM ###
-
-jQuery
-
- $('#myID').click(function() {
- alert('Clicked it!')
- })
-
-Vanilla JavaScript
-
- document.getElementById('myID').addEventListener('click', function(e) {
- alert('Clicked it!')
- })
-
-So easy.
-
-### Advanced Queries and Iteration ###
-
-jQuery
-
- $('.item').hide()
-
-Vanilla JavaScript
-
- var items = document.getElementsByClassName('.items')
- for (var i = 0; i < items.length; i++) {
- item[i].style.display = 'none'
- }
-
-We're starting to see the verbosity I mentioned above, but again, remember that we aren't loading in a massive third-party library!
-
-### Even More Advanced ###
-
-See Patrick Kunka's article [A Year Without jQuery](https://blog.wearecolony.com/a-year-without-jquery/)
-
-Patrick and I agree on many of the same points and his article articulates some helper functions that can be used to perform more advanced loops, child selection and child indexing. I highly recommend you read through his article.
-
-## Conclusion ##
-
-If you find that your requirements heavily rely on JavaScript for DOM manipulation, or that you need animations such as the ones provided by jQuery, then don't let me stop you. But if you only need some of what was covered above, or you want to put a priority on performance, then you should really consider going with plain vanilla JavaScript and leave the dependencies behind. You won't regret it.
\ No newline at end of file
diff --git a/views/pages/about.html b/views/pages/about.html
index e029114..73c7028 100644
--- a/views/pages/about.html
+++ b/views/pages/about.html
@@ -45,18 +45,8 @@
- Owner of
- this site,
-
currently working for
- this company,
-
former Senior Software Engineer at
- this company,
-
look what
- I can do,
-
contact me
- here
-
or read stuff I write
- here.
+ Check out my personal webite
+ here
diff --git a/views/pages/index.ejs b/views/pages/index.ejs
index 0509d62..88d66b1 100644
--- a/views/pages/index.ejs
+++ b/views/pages/index.ejs
@@ -25,14 +25,18 @@
-
So... we've been trying to get our 5 yr old son to finish drinking his milk.
-
One of the ways we have encouraged him is to explain that milk contains proteins that
- are good for the body and help build strong muscles. Skim is good, 1% is good, 2% is even better.
-
-
He thought for a while, and said...
-
"Dad, have you been drinking 100% milk?
-
Cause your muscles are sooo big!"
-
And that my friends is why being a dad is the best.
+
K0LEO
+
Find me on QRZ
+
+
QRV on DMR. Usually on TG 3146 (South Dakota), but occasionally I check out 31466, 3169, etc.
+
+
I got my Technician license in May of 2023, and immediately began tinkering with code plugs and operating in a hyper-local context with UHF/VHF and close friends that just started as well. One of my main reasons for getting licensed was to begin teaching/instructing some tactical comms courses at [OpenRangeTraining.com](http://OpenRangeTraining.com) over the course of the next year.
+
+
With my background as a Ground Radio Technician in the USAF, I have general knowledge of radios, antennas, and the basics of UHF/VHF signals. That being said, I know I have a lot to learn when it comes to communicating on HAM radio.
+
+
Looking forward to connecting with you!
+
+
73 from SD - Levi